
The Pitfalls of Agent-Based Monitors: Why Your MQ Downtime May Be Caused by the Monitors Themselves
The Pitfalls of Agent-Based Monitors: Why Your MQ Downtime May Be Caused by the Monitors Themselves
Section 1: The Traditional Agent-Based Model
The diagram below shows agents installed on every MQ host (e.g., each z/OS LPAR, each container, each VM).
These agents consume local CPU, memory, and network resources to poll MQ and forward data.
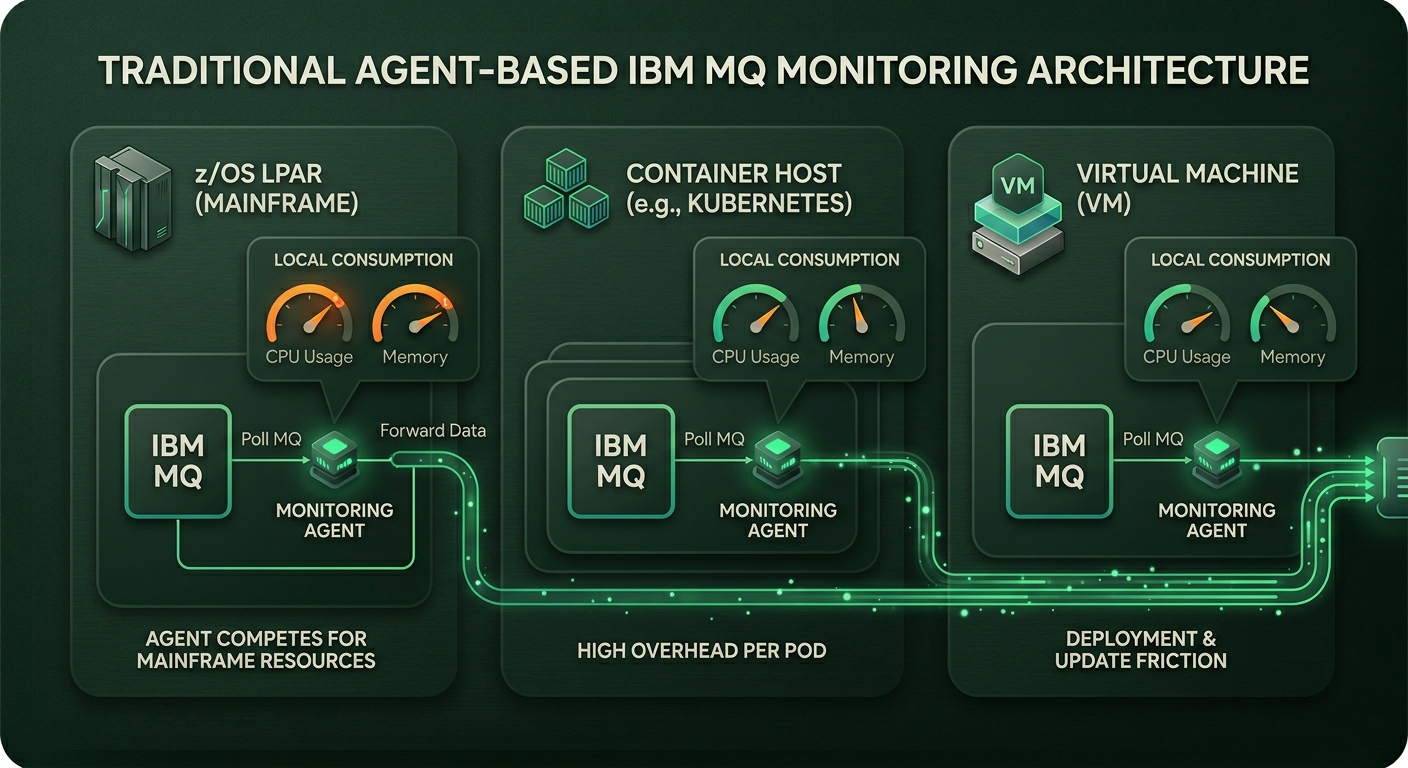
Section 2: Why the ‘Simple Agent’ Can Cause Downtime
Performance Impact: Agents running on the same host as the Queue Manager can consume CPU and memory, especially during peak load or data collection cycles.
Deployment Friction: Installing, updating, and maintaining agents across hundreds of containers or VMs creates significant overhead. A failure to deploy or update an agent is a “silent failure” that leaves an MQ instance unmonitored.
The “Monitor-Induced” Failure: An agent acting as an MQ client can be misconfigured, leading to:
Too many connections, exhausting channel instances.
Unrecognized certificates, blocking connection.
High check frequencies that appear as denial-of-service attacks.
Container Chaos: In Kubernetes or Native HA, pods are ephemeral. An agent bound to a specific pod ID will “lose” the queue manager when it restarts or fails over elsewhere. This leads to monitoring gaps and ‘black hole’ periods during exactly the failures you want to observe.
Section 3: The Agentless Alternative (Lamaxu as an Example)
The diagram below shows a central monitoring server connecting directly and remotely to each queue manager as a lightweight MQ client.

Benefits:
No Local Footprint: Zero agents on production systems means zero local CPU, memory, or disk usage.
Instant Deployment: No per-host installation. It’s a matter of a configuration update to connect to a new queue manager.
Following the Workload: In dynamic environments (cloud, Native HA), an agentless monitor can reconnect to the active instance after a failover, maintaining a continuous data stream.
Reduced Attack Surface: One secure connection point for monitoring, not thousands of distributed agents.
Section 4: When Agentless Makes the Most Sense
Hybrid Cloud & Containers (Kubernetes/OpenShift): For IBM MQ Native HA monitoring, where agents cannot easily be maintained.
z/OS and iSeries: These platforms are often extremely sensitive to third-party software. Agentless monitoring avoids complex mainframe software installation.
Large-Scale Deployments: With hundreds of queue managers, the operational overhead of agents becomes a major liability.
Security-First Environments: Agentless requires opening fewer ports and installing less code on critical systems.
Notes: Technical guide
Target audience: IT leaders and platform engineers frustrated with agent maintenance or MQ performance issues caused by monitoring tools
Date: 4 May 2026